编译原理¶
课程要求¶
- Homework=10% 一定要交!
- ClassQuizzes=10% 记得来!
- MidExam=15%. 努力复习拿高分。
- Labs=25% 布置后马上开始,多花时间,积极向助教寻求帮助,不要放弃。
- FinalExam=40% 平时分拿到40分以上,期末压力会小非常多。
- FinalExam < 40/100 ➔Final Grade < 60/100
Chapter 2:¶
DFA NFA LL(0) LR(0) LL(1) LR(1) SLR LALR
Chapter 5¶
Symbol Table¶
语义分析:定义联系使用,检查表达式类型正确否,抽象语法转化为易于生成中间代码的表示
5.1 符号表
- Symbol Table要干什么?
将标识符映射到它们的类型和储存位置。
- 加入定义
- 右定义覆盖左定义
-
到作用域末尾,区域binding丢掉
-
支持四个操作: insert lookup beginScope endScope
-
Multiple Symbol Table
像Java那样,支持多重作用域
而对于ML语言,则是没有前项引用,就累加下去
- 两种方式 Imperative Style(命令式)
从外面插入,从里面删除
命令式风格的方法则不需要申请多个符号表,自始至终在单个符号表上进行动态维护。其中每一项对应的不是一个变量的定义,而是变量定义的栈。
Functional Style(函数式)
函数式风格的方法在每次进入新的作用域时都需要申请一个新的符号表,而当离开该作用域时,就可以将该符号表销毁,相当于维护了一个符号表的栈。
-
怎么实现高效
-
命令式
使用哈希表进行新的binding插入,然后新插入的在左边
insert:做哈希得到index,相应位置插入binding
lookup:做哈希得到index,从index开始向下查找,直到找到binding
pop:做哈希得到index,hash表位置变为下一个
- 函数式
核心在于使得\(\sigma\)不被改变
也就是复制数组,使得新的作用域有新的binding。但是这样太大、太浪费,所以使用二叉搜索树。
Insert:Copy the nodes from the root to the parent of the inserted node
LookUp:从根节点开始,向下查找 O(logn)
总结来说就是命令式插入毁原来表,进入新scope需要额外标记来删, 函数式插入新环境拿一份旧环境走,退出回到旧环境
Symbol Table in Tiger¶
interface & implementation
typedef struct S_symbol_ *S_symbol;
S_symbol S_symbol (string); /* Symbol */ string S_name(S_symbol);
typedef struct TAB_table_ *S_table;
S_table S_empty( void);
void S_enter( S_table t,S_symbol sym, void *value); void *S_look( S_table t, S_symbol sym);
void S_beginScope( S_table t);
void S_endScope( S_table t);
static S_symbol mksymbol (string name , S_symbol next) {
S_symbol s = checked_malloc(sizeof(*s));
s->name = name; s->next = next;
return s;
}
S_symbol S_symbol (string name) {
int index = hash(name)%SIZE;
S_symbol syms = hashtable[index], sym;
for ( sym = syms; sym; sym = sym->next)
if (0 == strcmp(sym->name, name)) return sym;
sym = mksymbol(name,syms);
hashtable[index] = sym;
return sym;
}
string S_name (S_symbol sym) {
return sym->name;
}
// make a new S_Table
S_table S_empty(void) {
return TAB_empty();
}
// insert a binding
void S_enter(S_table t, S_symbol sym, void *value){ TAB_enter(t,sym,value);
}
// look up a symbol
void *S_look(S_table t, S_symbol sym) {
return TAB_look(t,sym);
}
static struct S_symbol_ marksym = { “<mark>”, 0 };
void S_beginScope ( S_table t) {
S_enter(t, &marksym, NULL);
}
void S_endScope( S_table t) {
S_symbol s;
do
s= TAB_pop(t);
while (s != &marksym);
}
使用辅助栈便于恢复那个最近的symbol
struct TAB_table_ {
binder table[TABSIZE];
void *top;
};
t->table[index] = Binder(key, value, t->table[index], t->top);
static binder Binder(void *key, void *value, binder next, void *prevtop) {
binder b = checked_malloc(sizeof(*b));
b->key = key; b->value=value; b->next=next;
b->prevtop = prevtop;
return b;
}
Type Checking¶
三个关键问题
- Valid的类型表达式
- 两个类型是否相同
- 类型检查规则
Types¶
- 基本类型 int, string
- 构建类型 由其他类型组成的records和arrays
Name Eq & Structural Eq
Tiger uses name Eq
只认名字不认结构
Environments for Type Checking
Type environment: symbol -> Ty_ty
Value environment:
symbol -> Ty_ty
symbol -> struct{Ty_tyList formals, Ty_ty result;}
Semant module实现了语义分析&类型检查
函数如下
Struct expty transVar (S_table venv, S_table tenv, A_var v); Struct expty transExp (S_table venv, S_table tenv, A_exp a); Void transDec (S_table venv, S_table tenv, A_dec d);
Ty_ty transTY (S_table tenv, A_ty a);
transExp recursive function
实现了type-checking和IR Generation
Type-Checking for Tiger¶
TransExp:类型检查表达式,查询和更新环境
可以在给定的两个环境下将输入的表达式标记上type(如果发现非法则报错)
接下来讲一个简单的"+"的类型检查
一些类型检查
Variable declarations¶
Type declarations¶
Function declarations¶
Recursive declarations¶
对于例子 type list = {first: int, rest: list}
use 2 passes 1. 先把所有的类型(headers)都放到一个表里 2. 然后再进行body的类型检查
对于函数也是一样的
在此提个要求:手搓整个流程和各个中间件搞清楚(写完删)
Chapter 6¶
Activation Records
当一个活动被调用的时候我们应该构建一个什么样的数据结构来保存它的状态
LIFO使用control stack来存储
每次当过程被调用,它的local variables和参数都被压入栈中 当过程返回的时候,栈顶的所有数据都被pop掉 这也被叫做活动过程 每一个live activity都对应一个activation record也叫做frame,在control stack中存储
实现为简单的栈是不够的,由于其批量性
垃圾 | 已分配
一个问题 Para Passing中出现覆盖
- 好 什么情况
引用传递 修改这些东西
Static Link
Display
Lambda Lefting
Higher Order Functions
6.2 Frames in Tiger Compiler¶
escape与否?
- 逃逸分析
出不出作用域
一些接口
不考察不需要tiger 主要是给自己的实现思路
Chapter 7¶
 以下是完善后的讲稿内容,针对三地址码(Three-Address Code, TAC)及其相关概念进行了更清晰的组织和补充说明:
以下是完善后的讲稿内容,针对三地址码(Three-Address Code, TAC)及其相关概念进行了更清晰的组织和补充说明:
三地址码(Three-Address Code, TAC)¶
基本形式¶
三地址码的基本形式如下:
x = y op z
x 是目标变量(通常是临时变量)。
- y 和 z 是操作数(可以是常量、变量或临时变量)。
- op 是操作符(如加法、减法、乘法等)。
三地址码的特点是:右侧最多只有一个操作符。对于复杂的表达式,需要将其分解为多个简单的三地址指令。
示例¶
例如,表达式 2*a + (b-3) 可以分解为以下三地址码:
t1 = 2 * a
t2 = b - 3
t3 = t1 + t2
四字段结构¶
每条三地址码指令通常由四个字段组成: 1. 操作符(op):表示具体的操作(如加法、减法等)。 2. 三个地址字段:分别用于存储操作数和结果的目标地址。
其他形式¶
除了基本的二元操作外,三地址码还可以表示其他形式的操作,例如:
- 单目操作:t2 = -t1
- 函数调用:CALL(f, args)
- 内存访问:MEM(e) 表示从内存中取值。
总之,三地址码没有严格的标准形式,但其核心思想是通过简单指令来表示复杂的计算过程。
中间表示(Intermediate Representation, IR)¶
三地址码是一种典型的中间表示(IR),用于编译器的中间阶段。以下是常见的 IR 表达式类型及其含义:
表达式(Exp)¶
-
CONST(i)
表示整数常量i。例如:CONST(5)表示常量5。 -
NAME(s)
表示符号名称s。例如:NAME(x)表示变量x。 -
TEMP(t)
表示临时变量t。例如:TEMP(t1)表示临时变量t1。 -
BINOP(op, e1, e2)
表示二元操作符op对两个表达式e1和e2的操作。例如:BINOP(+, TEMP(t1), CONST(5))表示t1 + 5。 -
MEM(e)
表示从内存地址e中取值。例如:MEM(TEMP(t1))表示从t1指向的内存地址读取值。 -
CALL(f, args/l)
表示函数调用,其中f是函数名,args是参数列表。例如:CALL("printf", [TEMP(t1)])表示调用printf(t1)。 -
ESEQ(stm, exp)
表示语句和表达式的组合。先执行语句stm,然后计算表达式exp。
有返回值的T_exp,没有返回值的T_stm,带有布尔值的表达式a conditional jump
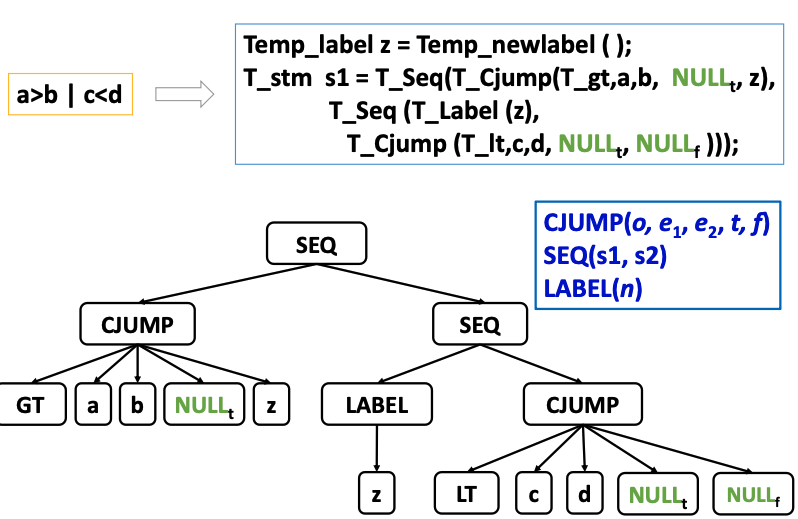
上图就是一个复杂语句拆分的例子
语句(Stm)¶
-
MOVE(TEMP t/dst, e/src)
表示赋值操作,将表达式e的值赋给变量t。例如:MOVE(TEMP(t1), BINOP(+, TEMP(t2), CONST(3)))表示t1 = t2 + 3。 -
MOVE(MEM(e_1), e_2)
表示将表达式e_2的值存储到内存地址e_1中。例如:MOVE(MEM(TEMP(t1)), CONST(5))表示将5存储到t1指向的内存地址。 -
EXP(e)
表示将表达式e转换为语句。例如:EXP(CALL("printf", [TEMP(t1)]))表示调用printf(t1)并忽略返回值。 -
JUMP(e, labs)
表示无条件跳转到标签labs。例如:JUMP(NAME("label1"))表示跳转到标签label1。 -
CJUMP(o, e1, e2, t, f)
表示条件跳转。如果e1 o e2为真,则跳转到标签t;否则跳转到标签f。例如:CJUMP(>, TEMP(t1), CONST(0), NAME("label1"), NAME("label2"))表示如果t1 > 0,则跳转到label1,否则跳转到label2。 -
SEQ(s1, s2)
表示顺序执行语句s1和s2。例如:SEQ(MOVE(TEMP(t1), CONST(5)), MOVE(TEMP(t2), CONST(10)))表示依次执行t1 = 5和t2 = 10。 -
LABEL(n)
表示标签n,用于标记代码中的跳转目标。例如:LABEL("label1")表示标签label1。
条件跳转示例¶
条件跳转是控制流的一种重要形式。例如,表达式 a > b || c < d 可以翻译为以下三地址码:
t1 = a > b
if t1 goto label_true
t2 = c < d
if t2 goto label_true
goto label_false
label_true:
// 执行 true 分支
label_false:
// 执行 false 分支
翻译过程¶
- 计算
a > b的结果,存入临时变量t1。 - 如果
t1为真,跳转到label_true。 - 否则,计算
c < d的结果,存入临时变量t2。 - 如果
t2为真,跳转到label_true。 - 如果两个条件都为假,跳转到
label_false。
总结¶
三地址码是编译器中一种重要的中间表示形式,具有以下特点: - 简单易懂,便于分析和优化。 - 支持复杂表达式的分解。 - 提供了丰富的语句和表达式类型,能够表示各种高级语言结构。
通过掌握三地址码及其相关概念,可以更好地理解编译器的工作原理,并为后续的优化和代码生成打下基础。
Chapter 8¶
IR规范化 转化成规范树 Basic Blocks and Traces
Canonical Trees
- No SEQ or ESEQ
- The parent of each CALL is eithrt a MOVE or an EXP
一些问题: 1.CJUMP实际上在汇编中如果没符合条件会继续执行 2.ESEQ中的stmt会带来副作用 3.CALL也会引起同样的问题
E.g., e1: a + 5, s: a = 5 假设有一个表达式 e1: a + 5 和一个语句 s: a = 5。 如果我们将 s 包含在 e1 中,形成一个新的表达式 a + (a = 5),那么这个表达式的值将取决于 a = 5 的执行时机。 如果先执行 a = 5,再计算 a + 5,结果将是 10;但如果先计算 a + 5,再执行 a = 5,结果将是原来的 a 加上 5。
- 不能有两个CALL,因为都使用相同的寄存器来传递参数,就可能出现参数值被覆盖的情况。
规范树: 重写成规范树: 1. 不能有SEQ和ESEQ 2. 每个CALL的父节点是MOVE或者EXP
特性: 1. 每个标准树最多有一个stmt比如根节点,其他都是表达式 2. CALL的子节点不能是CALL 推论:CALL的父节点必须是标准树根节点,最多可以有一个CALL因为EXP和MOVE仅仅可以有一个CALL
要干三件事: eliminate ESEQs move CALLs to TOP level eliminate SEQs
然后是过程
Taming Conditional Branches
Chapter 9¶
一条指令可以被表示为树形IR也称作tree pattern,使用nooverlapping tree pattern标识
使用J指令集讲解
每个tree pattern表示一个指令,像瓷砖一样拼接在一起,自底向上、从左到右,
最大覆盖瓦片覆盖
每一步找最大的瓦片,局部最优
Chapter 10¶
活性分析(Liveness Analysis)¶
活性分析是一种编译器优化技术,用于减少寄存器的使用。通过确定哪些变量在未来会被用到(即它们是活跃的),编译器可以更有效地分配寄存器,避免不必要的内存访问。
关键概念¶
- 活跃性:如果一个变量在某条边上之后会被使用,并且在这期间没有被重新定义,则该变量在此边上的状态被认为是活跃的。
- Live-in:若一个变量在节点的任意入边(in-edges)上是活跃的,则称它为该节点的live-in。
- Live-out:若一个变量在节点的任意出边(out-edges)上是活跃的,则称它为该节点的live-out。
相关术语¶
- out-edges:从当前节点出发的所有边。
- in-edges:指向当前节点的所有边。
- pred[n]:节点n的所有前驱节点集合。
- succ[n]:节点n的所有后继节点集合。
- def[n/a]:在节点n或语句a中定义的变量集合。
- use[n/a]:在节点n或语句a中使用的变量集合。
计算规则¶
- 如果变量a在任何后继节点m的live-in集合中,则a也在当前节点n的live-out集合中。
- 如果变量a在节点n的use集合中,则a也在n的live-in集合中。
- 如果变量a在n的live-out集合中但不在def集合中,则a也在n的live-in集合中。
以数学形式表示:
-
\[in[n] = use[n] \cup (out[n] - def[n])\]
-
\[out[n] = \bigcup_{s \in succ[n]} in[s]\]
示例¶
假设有如下情况:
- in[m1] = {d}, in[m2] = {e}
- out[n] = {d, e}
- 根据Rule 3: in[n] = {b} ∪ ({d, e} - empty) = {b, d, e}
- 根据Rule 1: out[p] = {b, d, e}
- 再次应用Rule 1: in[p] = {b, d, e}
集合语言表述¶
-
\[in[n] = use[n] \cup (out[n] - def[n])\]
-
\[out[n] = \bigcup_{s \in succ[n]} in[s]\]
使用Use-Def链进行分析¶
通过使用Use-Def链(每个变量的使用位置和定义位置之间的关系),可以在控制流图(CFG)上高效地执行整个流程的in-out分析。这种方法允许编译器静态地分析程序,决定何时何地变量是活跃的,从而更好地管理寄存器分配和内存访问。
静态与动态分析¶
- 静态分析是在控制流图(CFG)上进行的,不依赖于具体的输入数据。
- 动态分析则是在程序执行过程中进行的,能够考虑到实际运行时的数据流信息。然而,在这里讨论的主要是静态分析方法。
这种分析有助于编译器优化代码,提高程序执行效率。
冲突图¶
Chapter 11¶
基于图染色的寄存器分配问题 这两个问题都是NP-complete的
Coloring by Simplification¶
Build¶
构建出一个冲突图(就是那个语句中变量之间的冲突关系图)
Simplify¶
m有小于K个邻居,即可以递归地染色所有点
所以其自然地使用基于栈或者递归的算法用于染色,度小于K的点被移除,同时处理其邻居的度,直到没有这样的点为止
Spill¶
某个时刻其只剩下度大于K的点
我们可以选择一些点进行溢出到内存
即又称作乐观着色
即选出度大于K的点放入内存中,继续操作其后续的点,直到变为空图
Select¶
内存中点上色没懂
添加指令读出Actual Spill
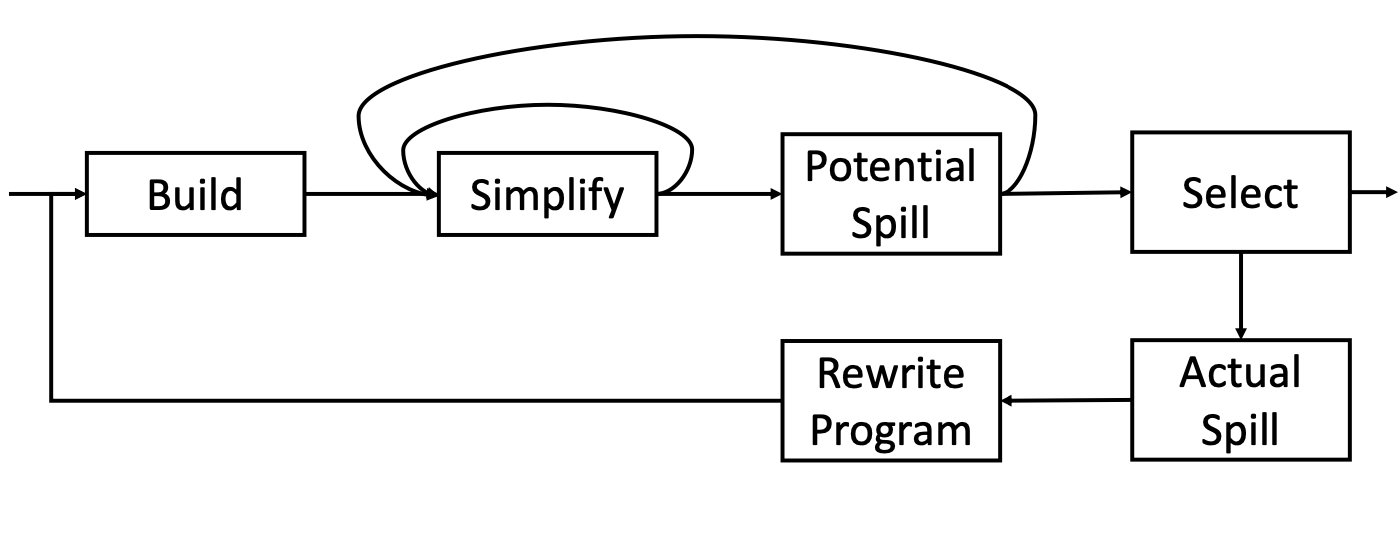
Coalescing¶
例如将movet1,t2中的t1和t2合并成新的寄存器
Briggs:¶
Nodes a and b can be coalesced if the resulting node ab will have fewer than K neighbors of significant degree
保证了K色图不会变成non-K色图
George¶
Nodes a and b can be coalesced if for every neighbor t of a, either t is a neighbor of b or t is of insignificant degree(<K)
Precolored Nodes¶
虽然t231是寄存器,但他会被优先spill所以输入内存